Background text#
We can either hard code information about the model into the script (not recommended) or we can store text in an external file and read it in. We recommend using markdown as streamlit has a function to render it.
1. Create a model information file.#
In a subdirectory called resources create a markdown file called model_info.md. Paste in the following text and save:
**A simple simulation model of a urgent care call centre process**
* Change the model parameters and rerun to see the effect on waiting times and utilisation of operators and nurses.
2. Read into python#
To read the contents of the markdown file you need to include some standard python code. We will create a function that reads the file and returns the contents as a string
def read_file_contents(file_name):
''''
Read the contents of a file.
Params:
------
file_name: str
Path to file.
Returns:
-------
str
'''
with open(file_name) as f:
return f.read()
3. Render the markdown#
We can use this function and then display the markdown using the st.markdown(str) function. Add the following line of code
st.markdown(read_file_contents('resources/model_info.md'))
4. The full listing#
The full code listing for our modified app is below. This is called app_with_markdown.py
"""
The code in this streamlit script modifies the basic script
we had for running a scenario
"""
import streamlit as st
from model import Experiment, multiple_replications
INTRO_FILE = 'resources/model_info.md'
def read_file_contents(file_name):
''''
Read the contents of a file.
Params:
------
file_name: str
Path to file.
Returns:
-------
str
'''
with open(file_name) as f:
return f.read()
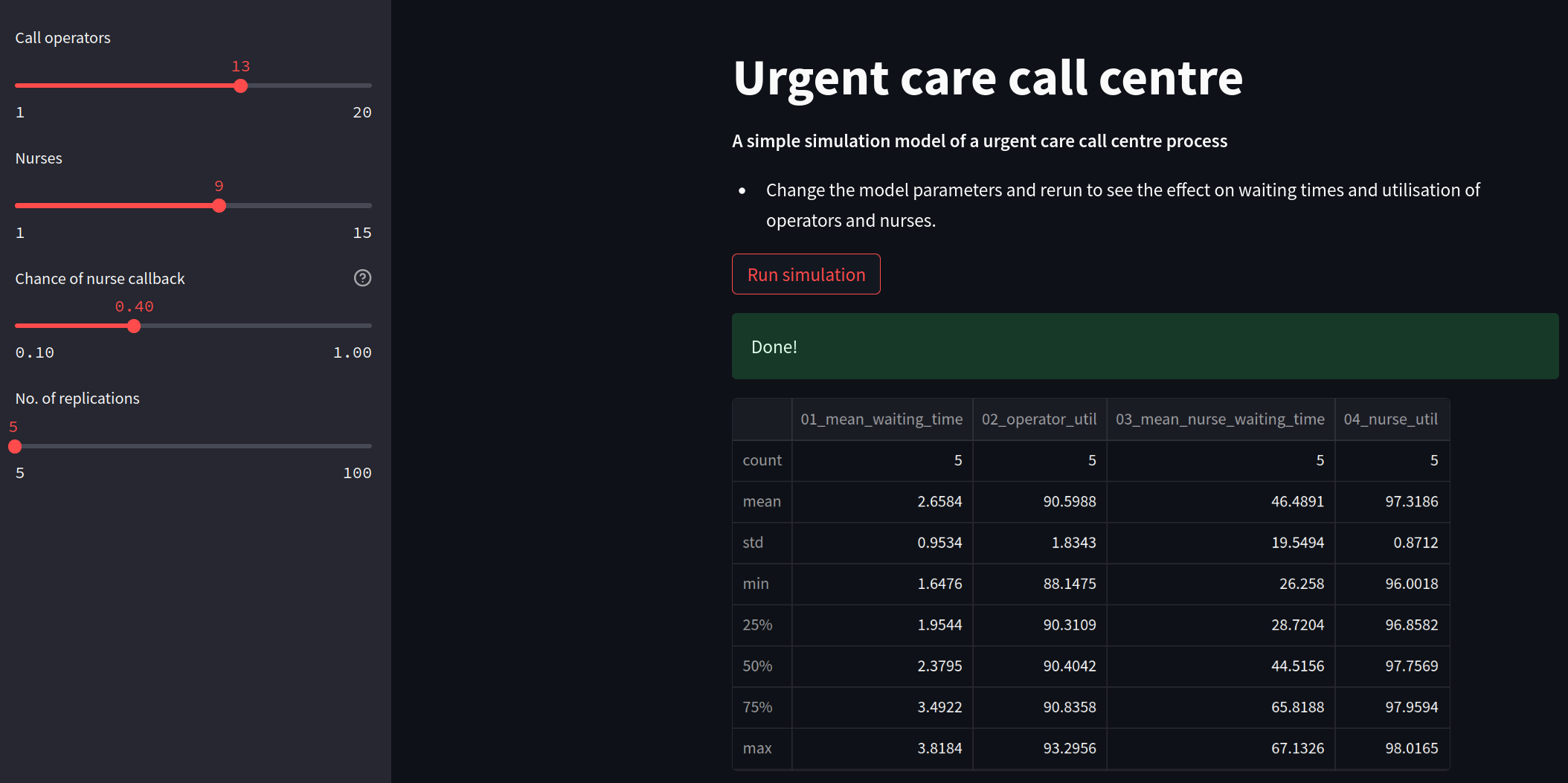
# We add in a title for our web app's page
st.title("Urgent care call centre")
# show the introductory markdown
st.markdown(read_file_contents(INTRO_FILE))
# side bar
with st.sidebar:
# set number of resources
n_operators = st.slider('Call operators', 1, 20, 13, step=1)
n_nurses = st.slider('Nurses', 1, 15, 9, step=1)
# set chance of nurse
chance_callback = st.slider('Chance of nurse callback', 0.1, 1.0, 0.4,
step=0.05, help='Set the chance of a call back')
# set number of replications
n_reps = st.slider("No. of replications", 5, 100, step=1)
# create experiment
exp = Experiment(n_operators=n_operators, n_nurses=n_nurses,
chance_callback=chance_callback)
# A user must press a streamlit button to run the model
if st.button("Run simulation"):
# add a spinner and then display success box
with st.spinner('Simulating the urgent care system...'):
# run multiple replications of experment
results = multiple_replications(exp, n_reps=n_reps)#
st.success('Done!')
# show results
st.dataframe(results.describe())
5 Read from a URL#
The code above is reading from a local file i.e. a file in a directory on a laptop’s harddrive. When the app is deployed to a server the file will not be found and the app will generate an error. The code below modifies the read_file_contents function to use urllib. In this case we are reading directly from the raw file on GitHub.
Notice that
INTRO_FILEis now a URL.
import urllib.request as request
INTRO_FILE = (
"https://raw.githubusercontent.com/health-data-science-OR/"
+ "simpy-streamlit-tutorial/main/content/03_streamlit/resources/model_info.md"
)
def read_file_contents(path):
"""
Download the content of a file from the GitHub Repo and return as a utf-8 string
Notes:
-------
adapted from 'https://github.com/streamlit/demo-self-driving'
Parameters:
----------
path: str
e.g. file_name.md
Returns:
--------
utf-8 str
"""
response = request.urlopen(path)
return response.read().decode("utf-8")